Google CloudのVPC
VPC (Virtual Private Cloud)とは
Google CloudのVirtual Private Cloud(VPC)は、クラウドベースのリソースとサービスに対してスケーラブルで柔軟性に優れたグローバルなネットワーキングを提供するサービスです。VPCは、Compute Engine仮想マシン(VM)インスタンス、Google Kubernetes Engine(GKE)クラスタ、サーバーレスワークロードなどにネットワーキング機能を提供します。
VPCネットワークは、Google Cloud内で仮想化されている点を除き、物理ネットワークと同じように考えることができます。VPCネットワークは、データセンター内のリージョン仮想サブネットワーク(サブネット)のリストで構成されるグローバルリソースであり、すべてグローバルな広域ネットワークで接続されています。
VPCネットワークの主な機能には以下が含まれます
ネットワーク接続: Compute Engine VMインスタンス、GKEクラスタ、サーバーレスワークロードなどに向けた接続を提供します。
ファイアウォールルール: 各VPCネットワークには、構成可能な分散仮想ファイアウォールが実装されています。ファイアウォールルールを使用すると、どのパケットをどの宛先に送信できるようにするかを制御できます。
ルート: VMインスタンスとVPCネットワークに対して、インスタンスから宛先(ネットワーク内部またはGoogle Cloudの外部)にトラフィックを送信する方法を通知します。
転送ルール: IPアドレス、プロトコル、ポートに基づいてVPCネットワーク内のGoogle Cloudリソースにトラフィックを転送します。
インターフェースとIPアドレス: VPCネットワークは、IPアドレスとVMネットワークインターフェース用の構成を提供します。
また、VPCネットワークはGoogle Cloud内で互いに論理的に隔離されており、他のGoogle Cloud利用者からは完全に独立したプライベートネットワークとなります。
とCopilot先生がおっしゃっています。

VPCネットワークを作ってみる
VPCの作成
ということで、VPCを作成してみます。
プロジェクトのトップページからVPCネットワークをクリック

こんなエラーが出るので、続行をクリック

Compute Engine APIを有効にする

どうやらGoogleCloudではAPIをプロジェクトごとに管理しているので、APIはプロジェクトごとに有効にするようです。
すでにdefaultのVPCがありますが、こちらは利用せず、新たにVPCの作成をします。
画面上部のVPCネットワークを作成をクリック

VPCとサブネット、VPC周りの設定を行っていきます。
まずはVPC名と説明などの設定。
MTUはデフォルトの1460のまま。ネットワークプロファイルは作成せずにサブネットは手動で作成したいのでカスタムにし、IPv6は設定しないこととします。
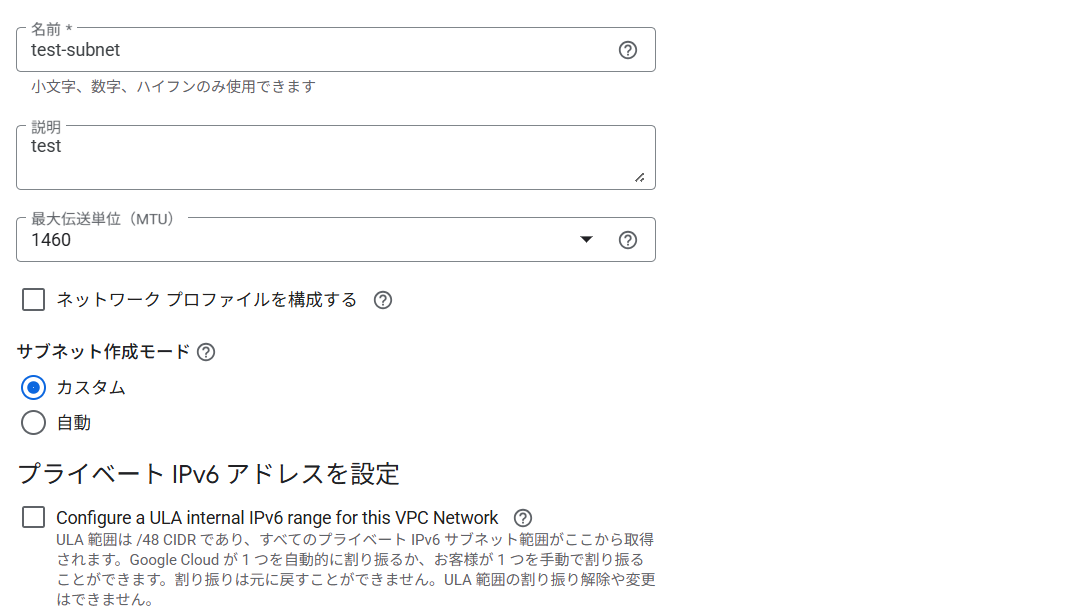
サブネットの作成、東京リージョンにtest-tokyoという名前のサブネットを作っています。
IPv4のみで、10.0.0.0/24、その他はすべてデフォルトのままです。

ファイアウォール ルールはデフォルトのまま。
ファイアウォールルールはAWSでいうセキュリティグループ、Azureでいうネットワークセキュリティグループと理解しています。これを細かく追うとそれだけでブログ1つかけそう。
設定としては、VPC内の通信許可、icmp/ssh/rdpの許可、自身からの送信の許可、Internetからの拒否が入っています。

高度庵設定はデフォルトのままにしました。
今回はCloudRouterは作らないので動的ルーティングは使わない…はず。

作成をクリック
作成したVPCが表示されます。

作成は簡単にできました。
どのクラウドもそうですが、細かい設定をせずにデフォルトで作成するのであれば簡単にできますし、デフォルト通りに作ってあげれば動くようになっているので助かります。